從 Punch Card 看資料儲存的原始邏輯
在資料庫誕生之前,資料儲存靠的是在紙卡上打洞。透過考古 Punch Card 的物理設計,看見欄位 、紀錄、Schema、批次處理等現代資料庫概念,早在數位時代之前就以實體形式存在。


2026 年的現在,儲存資料非常的簡單。當我們想在資料庫中寫入一筆員工資料時,一行 INSERT INTO employees (emp_id, dept, name) VALUES (42, 'E', 'SMITH'); 就搞定了。
但有一件事一直讓我很好奇:在資料庫誕生之前,在硬碟被發明之前,甚至在「檔案系統」這個概念存在之前——人們是怎麼儲存資料的?
最終的答案竟然是:打洞。
在那個年代,資料是一張張實體的紙卡——Punch Card(打孔卡),而非儲存在硬碟裡的電磁訊號。

Punch Card 不單單是歷史文物。如果仔細看它的設計,會發現許多今天習以為常的資料儲存概念——欄位、紀錄、批次處理——早在那個年代就已經以物理的形式存在了。
今天這篇文章,我們把時間倒回 1900 年代初期,透過考古 Punch Card,來理解資料儲存最原始的物理本質。
儲存邏輯的差異——當資料是物理的孔洞
在理解 Punch Card 之前,先看看現代電腦是如何儲存資料的。
現代電腦:一切都是抽象的
64 位元定址、虛擬記憶體、檔案系統,存入一個字串 "Hello" 時,它被編碼成一串 0 與 1 的電訊號,寫入 SSD 的快閃記憶體晶片裡。這些 0 跟 1 只是「邏輯上的位址」,不需要知道它實際住在哪一顆晶片的哪一個 Cell 裡。
作業系統做了一層又一層的抽象。我們只需要知道「檔案叫什麼名字」,剩下的事情,讓電腦去煩惱。
Punch Card 時代:Data is Physical
但在 Punch Card 的世界裡,這一切抽象都不存在。
用現代的眼光回頭看,一個孔洞就像是一個 bit,有洞代表 1(電路導通),沒洞代表 0(電路斷開)。但這裡有一個很重要的事實:當時的人根本不是這樣想的。
雖然「bit」的概念在 1947 年就由 John W. Tukey 在 Bell Labs 的備忘錄中提出(binary digit 的縮寫),隔年 Claude Shannon 也在經典論文中正式使用——時間上與打孔卡的巔峰期(1950-1960 年代)完全重疊。但打孔卡操作員不用 bit 來思考,是因為硬體架構就不是這樣運作的,並不是因為這個概念還不存在。
當時的資料處理高度依賴機械式與機電式的讀取結構。人們是以「Column」和「孔位組合」來理解資料,而不是現代數位運算中抽象的二進位邏輯。操作員不會認為自己儲存了一個 bit,心裡想的則是在第 3 個 Column 打了一個洞去代表某個字母:
- Column:卡片上的一格,存一個字元。
- Card:一張卡就是一筆紀錄。
- Deck:一疊卡就是一批資料。
那時候最主流的格式是 IBM 80-Column Format,由 IBM 的工程師 Clair D. Lake 在 1928 年設計。他用長方形的孔洞取代了更早期 Hollerith 卡的圓形孔洞,讓同樣大小的卡片能塞進將近兩倍的資料。一張標準的打孔卡有:
- 80 個 Column:代表你最多能存 80 個字元(一個字元可以是一個數字、英文字母、或是特殊符號)。
- 12 個 Row:每個 Column 裡有 12 個可以打洞的位置,由上到下排列。要表達哪一個字元,就在這 12 個位置中打出特定的組合。
換句話說,一張打孔卡就是一個 80 × 12 的格子。橫向 80 格決定「你能存幾個字元」,縱向 12 格決定「每個字元怎麼表達」。具體的編碼規則,我們在後面介紹 Hollerith Code 時會提到。
如果用現代的角度去算:80 × 12 = 960 個孔位,每個孔位都是「有洞或沒洞」的二元狀態,理論上可以承載 960 bits 的資訊——相當於 120 bytes。但一張卡片實際上只存了 80 個字元。這是因為 Hollerith Code 用 12 個位置來編碼一個字元,卻只會打 1 到 3 個洞,大部分位置是空的。這看起來像是在「浪費」空間,但 Hollerith Code 的目標就只是讓當時的機械式排序機和製表機,能用最簡單的電路來讀取和處理資料,而非最大化資訊密度。後來 ASCII 用 7 個 bit 就能表達 128 種字元,正是因為到了電子計算機的時代,不再需要遷就機械結構的限制。
看到這裡,有沒有覺得「80」這個數字很眼熟?
沒錯。為什麼很多 Terminal 的預設寬度是 80 字元?為什麼早期的 Code Style Guide 建議一行不超過 80 個字?
因為打孔卡就是 80 格寬。
而為什麼是 80,不是 60 或 100?這裡有個冷知識:
打孔卡的物理尺寸是 7⅜ × 3¼ 英寸——跟 1887 年的一美元鈔票一模一樣。Hollerith 當初沿用了鈔票的尺寸,是為了能直接使用現成的鈔票儲存設備和裁切工具。而 1928 年 IBM 把圓形孔洞改為長方形後,在這個固定大小的卡片上,能塞下的最大 Column 數就是 80。
所以「一行 80 個字」這條規則的源頭,並非特殊的偏好,完全是物理限制,帶來的影響直至今日。
最關鍵的差異:Schema 是物理的
在現代資料庫裡,Schema 是軟體定義的 Metadata。你可以隨時 ALTER TABLE 來修改欄位。改錯了?ROLLBACK 就好。
但在 1950 年代,Schema 是物理定義的。
必須事先約定好:Column 1-10 是姓名,Column 11-20 是電話號碼,Column 21-30 是地址。這些規則寫在一份紙本的「欄位對照表」上,所有操作員都要照著做。
這裡要區分兩件事:
- 字元編碼(Encoding):這是有標準的。Hollerith Code 規定了「A 怎麼打、3 怎麼打」,後來甚至在 1969-1970 年間被正式定為 American National Standard(ANSI X3.26-1970)。所以不管在哪家公司,字母 A 的打法都是一樣的。
- 欄位佈局(Schema / Layout):這完全沒有標準。A 公司的名字佔 Column 1-10,B 公司的名字佔 Column 5-15,各做各的。
換句話說,encoding 有標準,schema 沒標準。每個組織都在用自己的「方言」來安排欄位。某些行業會有約定俗成的慣例(例如 COBOL 程式卡有常見的 column 分配方式),但也不是強制的規格,更像是「大家都這麼做所以就變成了習慣」。
打錯了?只能把整張卡片丟掉,拿一張新的重來。
讓我們一起來回到過去,假設你是一個 1950 年代的工程師,老闆要你建立一批員工資料卡,儲存以下這筆資料:
{ Emp_ID: 42, Dept: "E", Name: "SMITH" }
你手上有一疊空白的打孔卡、一台打孔機,還有一份 Hollerith Code 對照表。要怎麼把這筆資料「寫」進去?
認識編碼系統:Hollerith Code
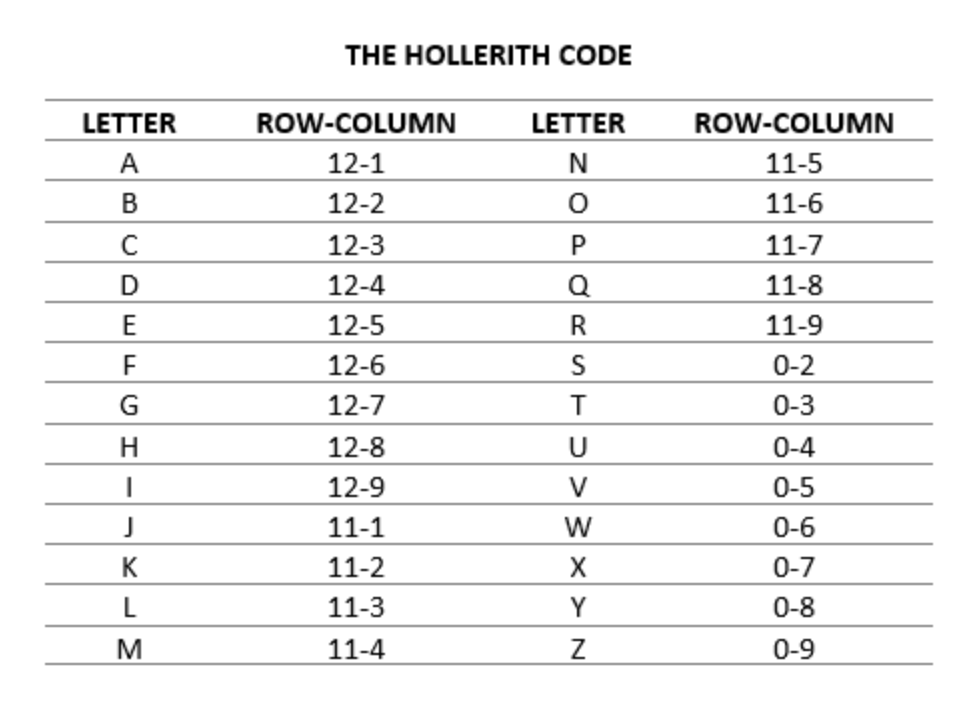
在 ASCII 誕生之前,打孔卡用的是 Hollerith Code(以打孔卡製表系統的發明者 Herman Hollerith 命名)。
一張卡片的 12 個 Row 分成兩個區域:
- Zone Row:最頂部的三個 Row,編號為 12、11、0。
- Digit Row:下方九個 Row,編號為 1 到 9。
數字只需要在對應的 Digit Row 打一個洞就好。但字母比較麻煩——每個字母需要兩個洞的組合,一個 Zone 洞加一個 Digit 洞。
這就像是一種「二維座標系統」:Zone 告訴你在哪個區,Digit 告訴你在區裡的第幾個位置。
欄位 1:Emp_ID(Integer)
假設我們把 Emp_ID 分配在 Column 1-2。ID 是 42,所以:
- Column 1:在 Digit Row「4」打一個洞 → 代表數字 4。
- Column 2:在 Digit Row「2」打一個洞 → 代表數字 2。
搞定,數字就是這麼簡單。
這也是為什麼在那個年代,工程師會盡量用數字來識別一切。不是因為每個字元只需要打一個洞——更重要的是,機器處理數字遠比處理字母簡單。
當時的機器一次只讀一個 Column 的一個 Row。數字只有一個洞,機器偵測到那個洞就能直接把卡片分到對應的槽裡。但字母有兩個洞(Zone + Digit),機器需要更複雜的電路來同時處理兩個訊號,速度也更慢。
所以那個時代能用編號就不會用文字,用 Employee ID 42 來識別員工,永遠比用名字 SMITH 好處理。
欄位 2:Dept(Letter)
假設 Dept 分配在 Column 3。我們要存字母 E(代表 Engineering 部門)。
E 是英文字母的第 5 個。在 Hollerith Code 裡,字母 A-I 對應 Zone 12 + Digit 1-9,J-R 對應 Zone 11 + Digit 1-9。所以 E 的編碼是:
- Zone 12 打一個洞
- Digit 5 打一個洞
一個字母,要打兩個洞。
雖然不管存字母還是數字,一個字元都只佔一個 Column,一張卡片能存的字元數不會改變。但字母的處理成本明顯更高:機器需要同時偵測 Zone Row 和 Digit Row 才能辨識一個字母,電路更複雜、處理速度更慢。相比之下,數字只需要偵測一個 Digit Row 就搞定了。
這就是為什麼那個時代的工程師偏好用數字代碼來表示類別——與其存部門代碼 E,不如直接存部門編號 1。是為了讓機器更快、更簡單地處理,而非為了省空間。
欄位 3:Name(String)
假設 Name 分配在 Column 4-20。我們要存 SMITH:
- S:Zone 0 + Digit 2(S 是第 19 個字母,屬於 S-Z 區段,Zone 為 0)
- M:Zone 11 + Digit 4(M 是第 13 個字母,屬於 J-R 區段)
- I:Zone 12 + Digit 9(I 是第 9 個字母,屬於 A-I 區段)
- T:Zone 0 + Digit 3
- H:Zone 12 + Digit 8
五個字母,打了十個洞。如果員工名字更長,洞數還會繼續累積。
這也解釋了為什麼早期的資料設計中,名字欄位的長度總是被嚴格限制——每多一個字母就多兩個洞,機器的處理負擔也跟著增加。在那個沒有刪除按鈕的年代,打錯任何一個洞,整張卡片就只能丟掉重來。
硬體的限制,同時也是資料格式的限制。
早期硬體與軟體的互動模式——沒有螢幕的 I/O
講完了「怎麼存」,接下來要聊「怎麼用」。
我的疑問:那個年代的人是不是拿著打孔卡,一張一張用肉眼去看洞在哪裡,來「讀取」資料?
答案是:幾乎不會。
雖然很多打孔卡的頂端會由機器印出對應的文字(叫做 Interpretation),方便人類快速核對。但真正的「讀取」是交給讀卡機來做的。
讀卡機的原理是這樣的:卡片在一個帶電的滾輪上移動,上方有一排金屬電刷。
- 沒洞的地方:紙卡是絕緣體,電刷被紙擋住,電路斷開 → 訊號 0。
- 有洞的地方:電刷穿過洞,直接接觸到下方的帶電滾輪,電路導通 → 訊號 1。
就這樣,物理的孔洞被轉換成了電訊號接著輸出印到卡片上。
那人類在這個流程裡扮演什麼角色呢?
首先是 Keypunch Operator(打孔員)。他們負責把原始資料(紙本表格、手寫文件)轉換成打孔卡。一個熟練的打孔員每小時可以打 3,000 到 6,000 個洞——聽起來很快,但換算下來也不過就是幾十張卡片的量。
接著是驗證。打孔員是人,人會犯錯。那怎麼確保打出來的資料是正確的?
當時有一種專門的機器叫驗孔機,例如 IBM 056。它的核心概念是 Double Entry Verification(雙重輸入驗證)——同一份資料由兩個人獨立輸入,機器自動比對差異:
- 第一個操作員在打孔機上,看著原始的紙本資料,把資料打成卡片。這一步產出了「已打孔的卡片」。
- 第二個操作員拿著這些已經打好的卡片,放進驗孔機。驗孔機跟打孔機長得很像,操作方式也幾乎一樣,但它不會打出新的洞。
- 第二個操作員看著同一份原始紙本資料,重新用鍵盤把資料完整地敲一遍。每敲一個鍵,驗孔機會在內部模擬打孔的邏輯,然後用感應針去偵測卡片上對應的位置是否真的有洞——把「第二個人敲的」跟「第一個人打的」逐格比對。
- 如果比對一致——通過,繼續下一格。如果不一致——機器立刻停住,紅色錯誤燈亮起,卡片停在出錯的那一格。這張卡片被抽出來重新打一張。
- 如果整張卡片都通過了,機器會在卡片的右側邊緣切一個小缺口,代表這張卡片已經通過驗證,資料是正確的。
注意:這是讓第二個人從頭到尾重做一次完整的輸入動作,而非「用眼睛檢查」。只有當兩個人獨立輸入的結果完全一致,資料才被視為正確。這個方法今天仍然存在——你在設定密碼時被要求「請再輸入一次密碼」,背後的邏輯跟 1950 年代的驗孔機是一樣的。
沒有螢幕,怎麼跑程式?
現在打開 VS Code,寫好程式碼,按一下 Run,結果就出現在螢幕上。但在 1950 年代,整個流程長這樣:
Step 1 — Input(輸入):
需要準備兩疊卡片。第一疊是程式卡片(Source Deck)——沒錯,程式碼本身也是打孔卡。每一行程式碼就是一張卡片。第二疊是數據卡片(Data Deck)—— 需要處理的資料。
把程式卡疊在數據卡前面,整疊放進讀卡機。
Step 2 — Load(載入):
機器先讀程式卡片,把邏輯載入 CPU 的暫存器和記憶體中。這時候 CPU 知道它等一下要做什麼了。
Step 3 — Process(處理):
接著機器開始讀數據卡片。每讀一張,CPU 就根據剛才載入的程式邏輯做運算。
Step 4 — Output(輸出):
計算結果怎麼輸出?兩種方式:機器打出新的打孔卡片(結果卡),或者直接列印在紙上。
能直接印出文字,是因為 Hollerith Code 的對照邏輯是寫死在機器的電路裡的。機器讀到「Zone 12 + Digit 4」這個孔洞組合,電路就知道這是字母 D,直接驅動印表機把 D 印出來。不需要軟體轉換,不需要查表——硬體本身就是那張表。
這整個過程是線性的、循序的。不能跳到第 50 張卡片去讀某筆資料——必須從第 1 張開始,一張一張往下跑。
這種「整疊卡片送進去、從頭到尾跑完」的運作方式,後來有了一個正式的名字:Batch Processing(批次處理),而今日習以為常的 Random Access(隨機存取)想讀第 50 筆就直接跳到第 50 筆,在那個時代是完全不可能的事。
回頭看 Punch Card 的設計,雖然笨重、慢、而且打錯一個洞就要整張重來——但它也建立了幾個影響至今的核心概念:
- Field(欄位):卡片上被約定好的某幾個 Column。
- Record(紀錄):一張卡片就是一筆紀錄。
- Batch(批次):一疊卡片一起處理。
- Schema:事先定義好的欄位對照規則。
- Data Validation:用驗孔機來確認資料正確性。
Punch Card 有多佔空間?我們來算一下。一張打孔卡存 80 個字元,換算成現代單位就是 80 bytes。用這個基準來換算:
- 5MB(大約一首 MP3):需要約 65,000 張打孔卡,疊起來大約 12 公尺高,重約 200 公斤,裝滿 33 個標準紙箱。
- 1GB(大約一部 YouTube 影片):需要約 1,340 萬張打孔卡,疊起來高達 2.4 公里——差不多是 4.7 座台北 101 的高度。總重約 42 公噸,需要動用將近 10 個標準貨櫃來搬運。
而且每張卡片都是 Read-Only after Write(寫入後唯讀),沒有覆寫的可能。一部 YouTube 影片的資料量,在打孔卡時代需要用貨櫃車隊來搬,而此時我們的手機裡可以同時裝幾百部。
當更多資料儲存的需求來臨時,人類需要一種能更快速讀寫、能重複利用、而且體積更小的介質,磁帶(Tape)就是接續著打孔卡的解答。看看人類如何從「摸得到的洞」跨越到「看不見的磁場」,以及這個跳躍如何催生出我們今天所有數位儲存的基礎。
參考資料:
共同作者:
- ClaudCode Opus 4.6
- Exa MCP

討論